Guarded Query Routing for Large Language Models
TLDR

GQR-bench measures how well a model can accurately route in-domain (ID) queries and reject out-of-distribution (OOD) queries. Although large language models such as Llama3.1:8B and GPT-4o-mini achieve the highest scores, they come with high latency. Conversely, models such as fastText and WideMLP offer a much better balance, with latencies in the sub-millisecond range that are orders of magnitude faster than LLMs. This benchmark challenges the reliance on computationally expensive LLMs, demonstrating that efficient classifiers are a more practical solution for guarded query routing.
Why is GQR important?
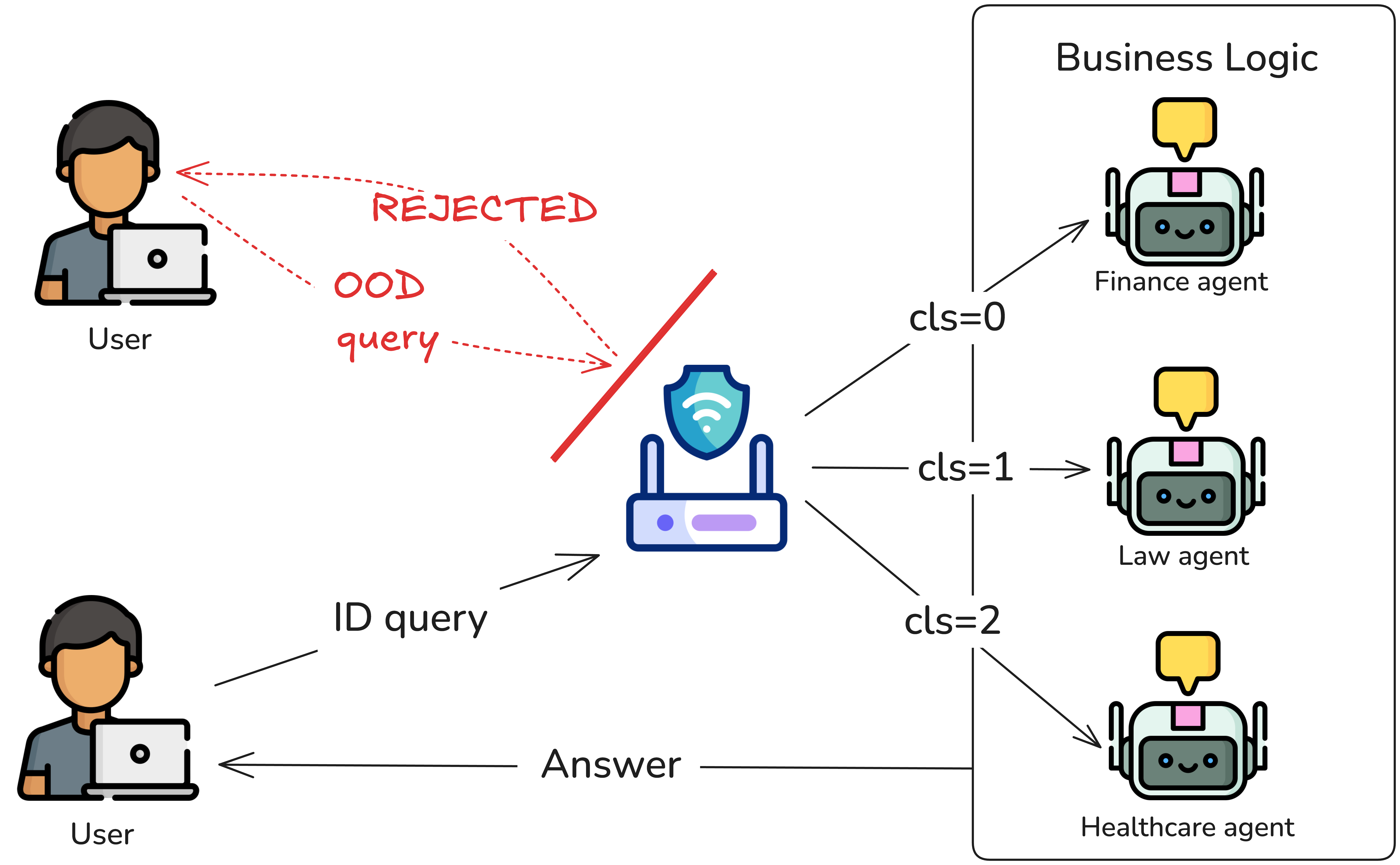
Guarded Query Routing (GQR) is important because modern systems increasingly use multiple Large Language Models (LLMs) calls to efficiently handle user requests. Although standard query routing directs a user's query to the relevant expert model (e.g. a query about contracts is directed to a legal model), it often fails to account for unexpected or inappropriate inputs. GQR addresses this issue by acting as a safeguard. Not only does it route valid, in-domain queries to the appropriate specialised "agent", it also identifies and rejects 'out-of-distribution' queries. These can include questions about completely unrelated topics, requests in different languages, or even unsafe and malicious inputs. By filtering these queries, GQR ensures that computational resources are not wasted, prevents models from providing incorrect or nonsensical answers and safeguards the system's overall integrity and safety.
Leaderboard
This table shows how well different models perform on in-distribution (ID) and out-of-distribution (OOD) datasets, which include both unsafe and out-of-domain data. The table presents the ID and OOD accuracies for each dataset, alongside three summary metrics. Unsafe Avg (the average accuracy across the five unsafe content datasets), OOD Accuracy and GQR Score.
| Model | Jigsaw | OLID | HateXplain | dkhate | TUKE SK | Web Q | ML Q | Unsafe Avg. | ID Acc. | OOD Acc. | GQR score |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Standard guardrail methods | |||||||||||
| Llama-Guard-3-1B | 51.40 | 61.40 | 91.47 | 12.77 | 20.13 | 2.31 | 0.00 | 47.43 | --- | 34.21 | --- |
| Llama-Guard-3-8B | 27.07 | 24.77 | 93.28 | 5.17 | 7.51 | 0.10 | 0.00 | 31.56 | --- | 22.56 | --- |
| NeMo Guardrails + Llama3.2:3B | 61.42 | 59.65 | 43.15 | 61.09 | 67.88 | 1.67 | 0.00 | 58.64 | --- | 58.64 | --- |
| NeMo Guardrails + Llama3.1:8B | 51.99 | 36.40 | 20.83 | 10.33 | 27.11 | 0.00 | 0.00 | 29.33 | --- | 29.33 | --- |
| NeMo Guardrails + GPT-4o-mini | 98.26 | 94.19 | 99.78 | 91.49 | 96.14 | 57.19 | 79.69 | 95.97 | --- | 95.97 | --- |
| Embedding similarity approaches | |||||||||||
| all-MiniLM-L6-v2 + Semantic Router (s=5, t=0.5) | 22.96 | 31.74 | 36.71 | 39.51 | 20.33 | 96.70 | 30.25 | 49.22 | 90.00 | 42.45 | 57.69 |
| bge-small-en-v1.5 + Semantic Router (s=5, t=0.5) | 15.15 | 28.95 | 32.67 | 31.91 | 12.41 | 95.42 | 31.25 | 24.22 | 90.70 | 35.39 | 50.91 |
| Routing based on large language models | |||||||||||
| Llama3.2:3B | 99.69 | 99.88 | 99.98 | 100.00 | 100.00 | 99.16 | 100.00 | 99.91 | 26.37 | 99.82 | 41.72 |
| Llama3.1:8B | 94.43 | 93.60 | 97.99 | 95.74 | 97.60 | 90.55 | 46.09 | 95.87 | 95.66 | 88.00 | 91.67 |
| GPT-4o-mini | 94.71 | 93.49 | 98.10 | 94.53 | 98.02 | 90.80 | 45.31 | 95.77 | 95.70 | 87.85 | 91.61 |
| Continuous bag-of-words classifiers | |||||||||||
| fastText | 74.46 | 61.51 | 54.46 | 74.77 | 83.11 | 70.37 | 63.28 | 69.66 | 95.80 | 68.85 | 80.12 |
| WideMLP (t=0.99) | 93.83 | 93.49 | 91.00 | 86.93 | 80.60 | 99.16 | 93.75 | 89.17 | 84.49 | 91.25 | 87.74 |
| WideMLP (t=0.90) | 87.87 | 83.26 | 77.56 | 71.73 | 56.93 | 95.57 | 89.84 | 75.47 | 90.91 | 80.39 | 85.33 |
| WideMLP (t=0.75) | 84.04 | 76.74 | 70.48 | 57.45 | 47.34 | 92.91 | 84.38 | 67.21 | 93.67 | 73.33 | 82.26 |
| Fine-tuned encoder-only language models | |||||||||||
| ModernBERT-base (t=0.99) | 27.10 | 17.91 | 18.06 | 10.33 | 2.50 | 62.30 | 0.00 | 15.18 | 99.94 | 19.74 | 32.97 |
| BERT-base-multilingual-cased (t=0.99) | 20.91 | 28.26 | 25.44 | 25.84 | 30.87 | 7.28 | 0.00 | 26.26 | 99.90 | 19.80 | 33.05 |
| Sentence embeddings + traditional classifiers | |||||||||||
| bge-small-en-v1.5 + SVM | 77.47 | 75.00 | 63.81 | 61.40 | 63.82 | 59.69 | 96.88 | 68.30 | 99.42 | 71.15 | 82.94 |
| bge-small-en-v1.5 + XGBoost | 81.95 | 68.26 | 72.15 | 47.72 | 59.02 | 58.81 | 92.97 | 65.82 | 98.78 | 68.70 | 81.04 |
| all-MiniLM-L6-v2 + SVM | 59.61 | 71.74 | 61.63 | 37.99 | 34.62 | 81.89 | 94.53 | 53.12 | 86.06 | 63.14 | 72.84 |
| all-MiniLM-L6-v2 + XGBoost | 47.57 | 77.44 | 53.14 | 57.45 | 60.17 | 95.47 | 89.84 | 59.15 | 92.93 | 68.73 | 79.02 |
| all-MiniLM-L12-v2 + MLP | 74.77 | 80.47 | 85.59 | 56.23 | 18.87 | 68.45 | 32.81 | 63.19 | 95.17 | 59.60 | 73.23 |
| TF-IDF + SVM | 24.58 | 26.16 | 21.72 | 75.38 | 96.98 | 54.87 | 87.50 | 48.96 | 37.76 | 55.31 | 49.26 |
| TF-IDF + XGBoost | 58.31 | 67.44 | 66.40 | 100.00 | 99.90 | 99.36 | 100.00 | 78.41 | 34.76 | 84.49 | 42.39 |
Benchmark Composition
GQR-Bench comprises existing datasets for evaluating the guarded query routing problem. The benchmark comprises in-distribution (ID) datasets for the target domains and out-of-distribution (OOD) datasets for robustness testing.
| Dataset | #train | #valid | #test |
|---|---|---|---|
| Datasets for target domains (in-distribution) | |||
| Law StackExchange Prompts | 9611 | 2402 | 2987 |
| Question-Answer Subject Finance Instruct | 9635 | 2409 | 2956 |
| Lavita ChatDoctor HealthCareMagic 100k | 9554 | 2389 | 3057 |
| Datasets for out-of-distribution queries | |||
| Jigsaw | 0 | 0 | 3214 |
| OLID | 0 | 0 | 860 |
| HateXplain | 0 | 0 | 5935 |
| dk_hate | 0 | 0 | 329 |
| HateSpeech Slovak | 0 | 0 | 959 |
| Machine Learning | 0 | 0 | 128 |
| Web Questions | 0 | 0 | 2032 |
GQR Score Explained
We use the harmonic mean as backbone of GQR-Score because it assess the model's performance on both in-domain (ID) and out-of-distribution (OOD) classification tasks. The harmonic mean is a stringent measure of combined performance because it heavily penalises imbalances between the two accuracy scores. Mathematically, given ID accuracy AccID and OOD accuracy AccOOD, the harmonic mean H is calculated as follows:
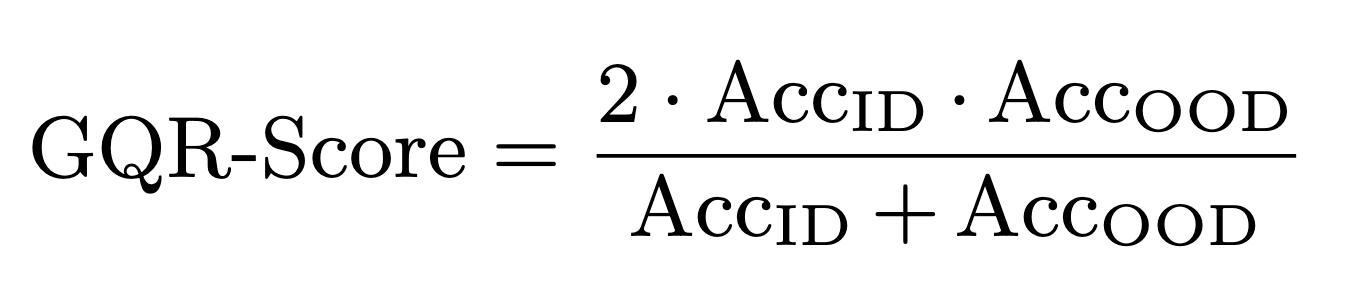
This harmonic mean acts as an overall performance indicator for ID and OOD queries, providing valuable insight into guarded query routing, where models must correctly route ID queries and identify OOD queries. This means that models must be able to tackle both classification tasks simultaneously to attain a high GQR score. In practical settings, this balanced measure is important because errors in either area can impact the system's overall utility and user confidence.
BibTeX
@incollection{gqrbench2025,
title={Guarded Query Routing for Large Language Models},
author={Richard Šléher and William Brach and Tibor Sloboda and Kristián Košťál and Lukas Galke},
booktitle={ECAI 2025},
year={2025},
pages={4129-4136},
publisher={IOS Press}
}